目前接触到的基本上都是Web端的性能测试,都是基于HTTP协议的,这里对HTTP协议做个简单的认识:
介绍
官方概念不多说,简单来说,就是一个基于应用层的通信规范:双方要进行通信,大家都要遵守一个规范,这个规范就是HTTP协议。
HTTP三点注意事项:
- HTTP是无连接
无连接的含义是限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。采用这种方式可以节省传输时间。 - HTTP是媒体独立的
这意味着,只要客户端和服务器知道如何处理的数据内容,任何类型的数据都可以通过HTTP发送。客户端以及服务器指定使用适合的MIME-type内容类型。 - HTTP是无状态
HTTP协议是无状态协议。同一个客户端的这次请求和上次请求是没有对应关系,对http服务器来说,它并不知道这两个请求来自同一个客户端。 为了解决这个问题, Web程序引入了Cookie机制来维护状态.
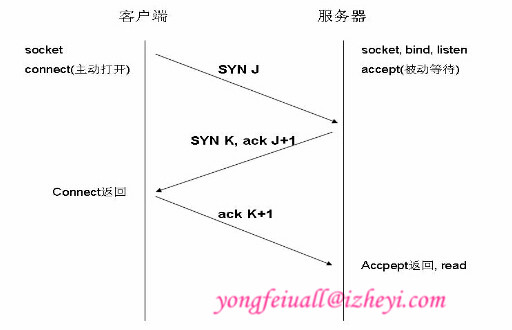
第一次握手:建立连接时,客户端发送syn包(syn=j)到服务器,并进入SYN_SENT状态,等待服务器确认;SYN:同步序列编号(Synchronize Sequence Numbers)。
第二次握手:服务器收到syn包,必须确认客户的SYN(ack=j+1),同时自己也发送一个SYN包(syn=k),即SYN+ACK包,此时服务器进入SYN_RECV状态;
第三次握手:客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=k+1),此包发送完毕,客户端和服务器进入ESTABLISHED(TCP连接成功)状态,完成三次握手。
工作流程
一次HTTP操作称为一个事务,其工作过程可分为四步:
- 首先客户机与服务器需要建立连接。只要单击某个超级链接,HTTP的工作开始。
- 建立连接后,客户机发送一个请求给服务器,请求方式的格式为:统一资源标识符(URL)、协议版本号,后边是MIME信息包括请求修饰符、客户机信息和可能的内容。
- 服务器接到请求后,给予相应的响应信息,其格式为一个状态行,包括信息的协议版本号、一个成功或错误的代码,后边是MIME信息包括服务器信息、实体信息和可能的内容。
- 客户端接收服务器所返回的信息通过浏览器显示在用户的显示屏上,然后客户机与服务器断开连接。
如果在以上过程中的某一步出现错误,那么产生错误的信息将返回到客户端,有显示屏输出。对于用户来说,这些过程是由HTTP自己完成的,用户只要用鼠标点击,等待信息显示就可以了
消息结构
Request 消息分为3部分,第一部分叫请求行, 第二部分叫请求头部, 第三部分是body。header和body之间有个空行。
Response消息的结构, 和Request消息的结构基本一样。 同样也分为三部分,第一部分叫状态行, 第二部分叫消息报头,第三部分是响应正文。header和body之间也有个空行。
请求头信息
HTTP最常见的请求头如下:
- Accept:浏览器可接受的MIME类型;
- Accept-Charset:浏览器可接受的字符集;
- Accept-Encoding:浏览器能够进行解码的数据编码方式,比如gzip。Servlet能够向支持gzip的浏览器返回经gzip编码的HTML页面。许多情形下这可以减少5到10倍的下载时间;
- Accept-Language:浏览器所希望的语言种类,当服务器能够提供一种以上的语言版本时要用到;
- Authorization:授权信息,通常出现在对服务器发送的WWW-Authenticate头的应答中;
- Connection:表示是否需要持久连接。如果Servlet看到这里的值为“Keep-Alive”,或者看到请求使用的是HTTP 1.1(HTTP 1.1默认进行持久连接),它就可以利用持久连接的优点,当页面包含多个元素时(例如Applet,图片),显著地减少下载所需要的时间。要实现这一点,Servlet需要在应答中发送一个Content-Length头,最简单的实现方法是:先把内容写入ByteArrayOutputStream,然后在正式写出内容之前计算它的大小;
- Content-Length:表示请求消息正文的长度;
- Cookie:这是最重要的请求头信息之一;
- From:请求发送者的email地址,由一些特殊的Web客户程序使用,浏览器不会用到它;
- Host:初始URL中的主机和端口;
- If-Modified-Since:只有当所请求的内容在指定的日期之后又经过修改才返回它,否则返回304“Not Modified”应答;
- Pragma:指定“no-cache”值表示服务器必须返回一个刷新后的文档,即使它是代理服务器而且已经有了页面的本地拷贝;
- Referer:包含一个URL,用户从该URL代表的页面出发访问当前请求的页面。
- User-Agent:浏览器类型,如果Servlet返回的内容与浏览器类型有关则该值非常有用;
- UA-Pixels,UA-Color,UA-OS,UA-CPU:由某些版本的IE浏览器所发送的非标准的请求头,表示屏幕大小、颜色深度、操作系统和CPU类型。
响应头信息
- Allow:服务器支持哪些请求方法(如GET、POST等);
- Content-Encoding:文档的编码(Encode)方法。只有在解码之后才可以得到Content-Type头指定的内容类型。利用gzip压缩文档能够显著地减少HTML文档的下载时间。Java的GZIPOutputStream可以很方便地进行gzip压缩,但只有Unix上的Netscape和Windows上的IE 4、IE 5才支持它。因此,Servlet应该通过查看Accept-Encoding头(即request.getHeader(“Accept-Encoding”))检查浏览器是否支持gzip,为支持gzip的浏览器返回经gzip压缩的HTML页面,为其他浏览器返回普通页面;
- Content-Length:表示内容长度。只有当浏览器使用持久HTTP连接时才需要这个数据。如果你想要利用持久连接的优势,可以把输出文档写入ByteArrayOutputStram,完成后查看其大小,然后把该值放入Content-Length头,最后通过byteArrayStream.writeTo(response.getOutputStream()发送内容;
- Content-Type: 表示后面的文档属于什么MIME类型。Servlet默认为text/plain,但通常需要显式地指定为text/html。由于经常要设置Content-Type,因此HttpServletResponse提供了一个专用的方法setContentTyep。 可在web.xml文件中配置扩展名和MIME类型的对应关系;
- Date:当前的GMT时间。你可以用setDateHeader来设置这个头以避免转换时间格式的麻烦;
- Expires:指明应该在什么时候认为文档已经过期,从而不再缓存它。
- Last-Modified:文档的最后改动时间。客户可以通过If-Modified-Since请求头提供一个日期,该请求将被视为一个条件GET,只有改动时间迟于指定时间的文档才会返回,否则返回一个304(Not Modified)状态。Last-Modified也可用setDateHeader方法来设置;
- Location:表示客户应当到哪里去提取文档。Location通常不是直接设置的,而是通过HttpServletResponse的sendRedirect方法,该方法同时设置状态代码为302;
- Refresh:表示浏览器应该在多少时间之后刷新文档,以秒计。除了刷新当前文档之外,你还可以通过
setHeader("Refresh", "5; URL=http://host/path")让浏览器读取指定的页面。注意这种功能通常是通过设置HTML页面HEAD区的<META HTTP-EQUIV="Refresh" CONTENT="5;URL=http://host/path">实现,这是因为,自动刷新或重定向对于那些不能使用CGI或Servlet的HTML编写者十分重要。但是,对于Servlet来说,直接设置Refresh头更加方便。注意Refresh的意义是“N秒之后刷新本页面或访问指定页面”,而不是“每隔N秒刷新本页面或访问指定页面”。因此,连续刷新要求每次都发送一个Refresh头,而发送204状态代码则可以阻止浏览器继续刷新,不管是使用Refresh头还是。注意Refresh头不属于HTTP 1.1正式规范的一部分,而是一个扩展,但Netscape和IE都支持它。
Get & Post
Http协议定义了很多与服务器交互的方法,最基本的有4种,分别是GET,POST,PUT,DELETE. 一个URL地址用于描述一个网络上的资源,而HTTP中的GET, POST, PUT, DELETE就对应着对这个资源的查,改,增,删4个操作。 我们最常见的就是GET和POST,占90%以上,多数是Get请求。GET一般用于获取/查询资源信息,而POST一般用于更新资源信息.
我们看看GET和POST的区别
- GET提交的数据会放在URL之后,以?分割URL和传输数据,参数之间以&相连,如EditPosts.aspx?name=test1&id=123456. POST方法是把提交的数据放在HTTP包的Body中.
- GET提交的数据大小有限制(因为浏览器对URL的长度有限制),而POST方法提交的数据没有限制.
- GET方式需要使用Request.QueryString来取得变量的值,而POST方式通过Request.Form来获取变量的值。
- GET方式提交数据,会带来安全问题,比如一个登录页面,通过GET方式提交数据时,用户名和密码将出现在URL上,如果页面可以被缓存或者其他人可以访问这台机器,就可以从历史记录获得该用户的账号和密码.
状态码
状态码分类
1** 信息,服务器收到请求,需要请求者继续执行操作2** 成功,操作被成功接收并处理3** 重定向,需要进一步的操作以完成请求4** 客户端错误,请求包含语法错误或无法完成请求5** 服务器错误,服务器在处理请求的过程中发生了错误
状态码列表





常见的HTTP状态码
200 - 请求成功
301 - 资源(网页等)被永久转移到其它URL
404 - 请求的资源(网页等)不存在
500 - 内部服务器错误
Cookie & Session
Cookie和Session都为了用来保存状态信息,都是保存客户端状态的机制,它们都是为了解决HTTP无状态的问题而所做的努力。
Cookie和Session有以下明显的不同点:
- Cookie将状态保存在客户端,Session将状态保存在服务器端;
- Cookies是服务器在本地机器上存储的小段文本并随每一个请求发送至同一个服务器。Cookie最早在RFC2109中实现,后续RFC2965做了增强。网络服务器用HTTP头向客户端发送cookies,在客户终端,浏览器解析这些cookies并将它们保存为一个本地文件,它会自动将同一服务器的任何请求缚上这些cookies。Session并没有在HTTP的协议中定义;
- Session是针对每一个用户的,变量的值保存在服务器上,用一个sessionID来区分是哪个用户session变量,这个值是通过用户的浏览器在访问的时候返回给服务器,当客户禁用cookie时,这个值也可能设置为由get来返回给服务器;
- 就安全性来说:当你访问一个使用session 的站点,同时在自己机子上建立一个cookie,建议在服务器端的SESSION机制更安全些.因为它不会任意读取客户存储的信息。
Session
Session机制是一种服务器端的机制,服务器使用一种类似于散列表的结构(也可能就是使用散列表)来保存信息。
当程序需要为某个客户端的请求创建一个session的时候,服务器首先检查这个客户端的请求里是否已包含了一个session标识 - 称为 session id,如果已包含一个session id则说明以前已经为此客户端创建过session,服务器就按照session id把这个 session检索出来使用(如果检索不到,可能会新建一个),如果客户端请求不包含session id,则为此客户端创建一个session并且生成一个与此session相关联的session id,session id的值应该是一个既不会重复,又不容易被找到规律以仿造的字符串,这个 session id将被在本次响应中返回给客户端保存。
Cookie
服务器在响应消息中用Set-Cookie头将Cookie的内容回送给客户端,客户端在新的请求中将相同的内容携带在Cookie头中发送给服务器。从而实现会话的保持。
缓存
WEB缓存(cache)位于Web服务器和客户端之间。
缓存会根据请求保存输出内容的副本,例如html页面,图片,文件,当下一个请求来到的时候:如果是相同的URL,缓存直接使用副本响应访问请求,而不是向源服务器再次发送请求。
常见流程:
服务器收到请求时,会在200OK中回送该资源的Last-Modified和ETag头,客户端将该资源保存在cache中,并记录这两个属性。当客户端需要发送相同的请求时,会在请求中携带If-Modified-Since和If-None-Match两个头。两个头的值分别是响应中Last-Modified和ETag头的值。服务器通过这两个头判断本地资源未发生变化,客户端不需要重新下载,返回304响应。
HTTP协议定义了相关的消息头来使WEB缓存尽可能好的工作。


