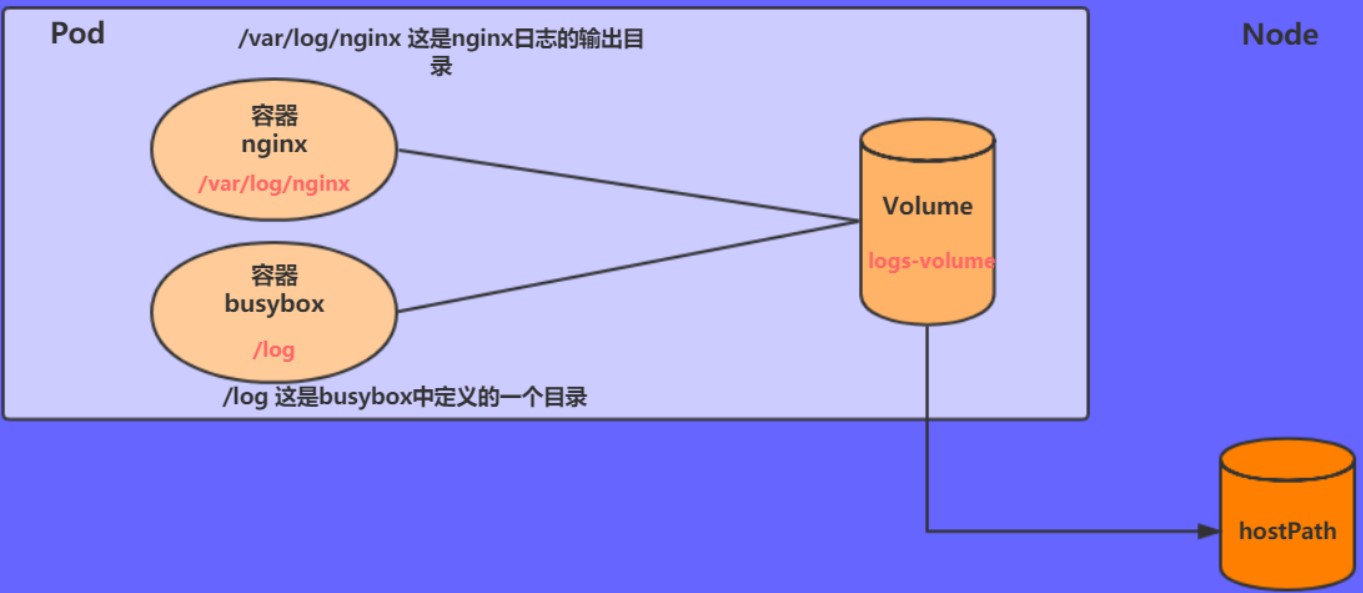
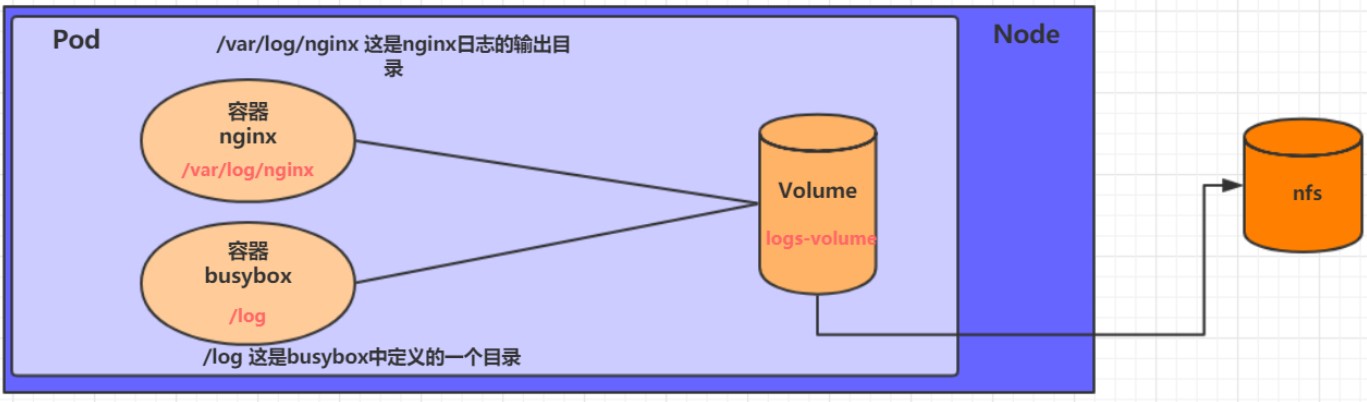
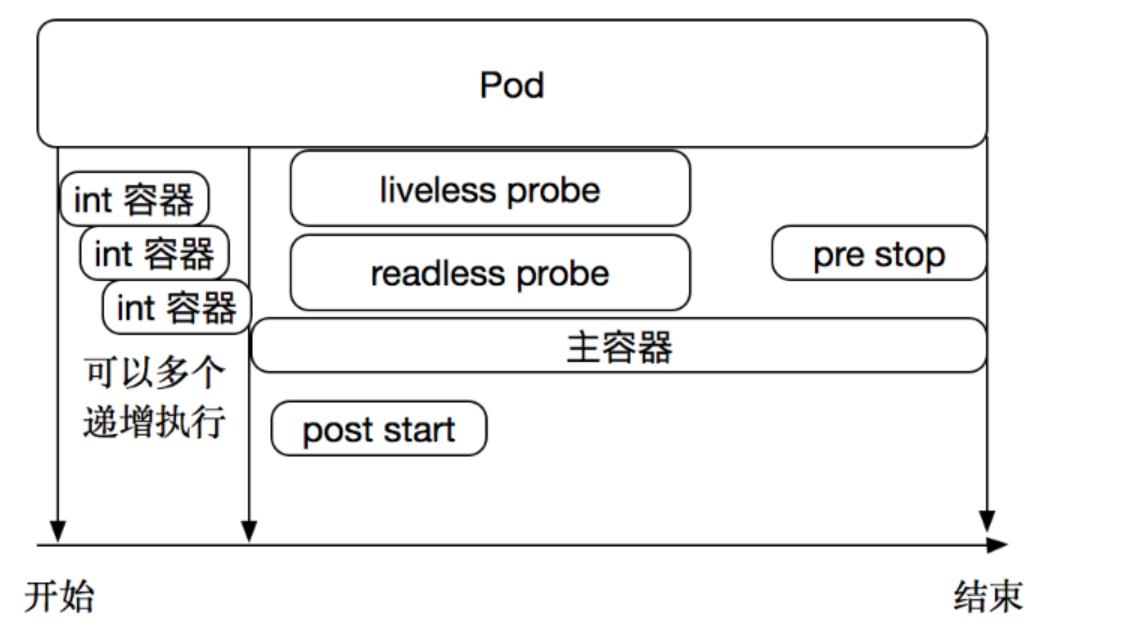
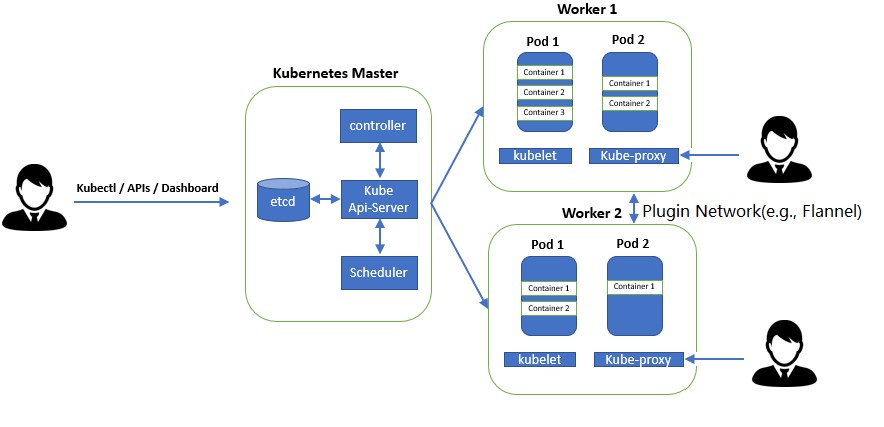
kubernetes还开发了一个基于web的用户界面(Dashboard)。用户可以使用Dashboard部署容器化的应用,还可以监控应用的状态,执行故障排查以及管理kubernetes中各种资源。
部署
下载yaml
1
[root@master ~]# wget https://raw.githubusercontent.com/kubernetes/dashboard/v2.0.0/aio/deploy/recommended.yaml --2021-10-18 10:40:54-- https://raw.githubusercontent.com/kubernetes/dashboard/v2.0.0/aio/deploy/recommended.yaml 正在解析主机 raw.githubusercontent.com (raw.githubusercontent.com)... 185.199.108.133, 185.199.111.133, 185.199.110.133, ... 正在连接 raw.githubusercontent.com (raw.githubusercontent.com)|185.199.108.133|:443... 已连接。 已发出 HTTP 请求,正在等待回应... 200 OK 长度:7552 (7.4K) [text/plain] 正在保存至: “recommended.yaml” 100%[==============================================================================================================>] 7,552 2.14KB/s 用时 3.4s
配置并运行Dashboard
1
# 新增type: NodePort 和 nodePort:31443,以便能实现非本机访问 kind: Service apiVersion: v1 metadata: labels: k8s-app: kubernetes-dashboard name: kubernetes-dashboard namespace: kubernetes-dashboard spec: type: NodePort ports: - port: 443 targetPort: 8443 nodePort: 31443 selector: k8s-app: kubernetes-dashboard # 部署 [root@master ~]# kubectl create -f recommended.yaml namespace/kubernetes-dashboard created serviceaccount/kubernetes-dashboard created service/kubernetes-dashboard created secret/kubernetes-dashboard-certs created secret/kubernetes-dashboard-csrf created secret/kubernetes-dashboard-key-holder created configmap/kubernetes-dashboard-settings created role.rbac.authorization.k8s.io/kubernetes-dashboard created clusterrole.rbac.authorization.k8s.io/kubernetes-dashboard created rolebinding.rbac.authorization.k8s.io/kubernetes-dashboard created clusterrolebinding.rbac.authorization.k8s.io/kubernetes-dashboard created deployment.apps/kubernetes-dashboard created service/dashboard-metrics-scraper created deployment.apps/dashboard-metrics-scraper created # 查看 [root@master ~]# kubectl get pod,svc -n kubernetes-dashboard NAME READY STATUS RESTARTS AGE pod/dashboard-metrics-scraper-c79c65bb7-spq7w 1/1 Running 0 88s pod/kubernetes-dashboard-56484d4c5-8v84c 1/1 Running 0 88s NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/dashboard-metrics-scraper ClusterIP 10.96.123.22 <none> 8000/TCP 88s service/kubernetes-dashboard NodePort 10.106.25.93 <none> 443:31443/TCP 88s
创建访问账户
1
# 创建账号 [root@k8s-master01-1 ~]# kubectl create serviceaccount dashboard-admin -n kubernetes-dashboard # 授权 [root@k8s-master01-1 ~]# kubectl create clusterrolebinding dashboard-admin-rb --clusterrole=cluster-admin --serviceaccount=kubernetes-dashboard:dashboard-admin # 获取账号token [root@master ~]# kubectl get secrets -n kubernetes-dashboard | grep dashboard-admin dashboard-admin-token-k6pp4 kubernetes.io/service-account-token 3 32s [root@master ~]# kubectl describe secrets dashboard-admin-token-k6pp4 -n kubernetes-dashboard Name: dashboard-admin-token-k6pp4 Namespace: kubernetes-dashboard Labels: <none> Annotations: kubernetes.io/service-account.name: dashboard-admin kubernetes.io/service-account.uid: 29dc2734-490e-4b03-bdad-a2574ac8ef59 Type: kubernetes.io/service-account-token Data ==== ca.crt: 1025 bytes namespace: 20 bytes token: eyJhbGciOiJSUzI1NiIsImtpZCI6InplRkxEdGNqbk1md0tyNnV1a0JHSy1OMml4Y2Q1a1g1QU5qMDRsdkZJTDgifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlcm5ldGVzLWRhc2hib2FyZCIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJkYXNoYm9hcmQtYWRtaW4tdG9rZW4tazZwcDQiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC5uYW1lIjoiZGFzaGJvYXJkLWFkbWluIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZXJ2aWNlLWFjY291bnQudWlkIjoiMjlkYzI3MzQtNDkwZS00YjAzLWJkYWQtYTI1NzRhYzhlZjU5Iiwic3ViIjoic3lzdGVtOnNlcnZpY2VhY2NvdW50Omt1YmVybmV0ZXMtZGFzaGJvYXJkOmRhc2hib2FyZC1hZG1pbiJ9.afoxaaCkhTggDxuiP13yC_fyd6yTKyHdB_0eSMqBZxpHR4jGLJnaMXO4WlHY07yPuo9vWA5izEv6qwfhueZi2dFkgMxdQdGKKQXsv1_qpnh9LxztxseYVXV9BNc55XUS2LIZg1If94tMd_meECNm8dVNuJIQd_0IN_cEG0csZNYoYbbyYgBkKJNNxLhmRotpuQ1QDxsEWVnLI8lhHr_vcX99Szv2IAqq2jiUWcsFTzIpAaSESUF8F1DxfaaWIpw-Jq9GnQILXb_HpIuFHW2ijaUik5V57w-oUIq6nSrQCBpxaTyY_ehQHLUUm4D3Bx9uYBhqlaZBVIvYTui_S_Rs0w
验证
在登录页面上输入上面的token
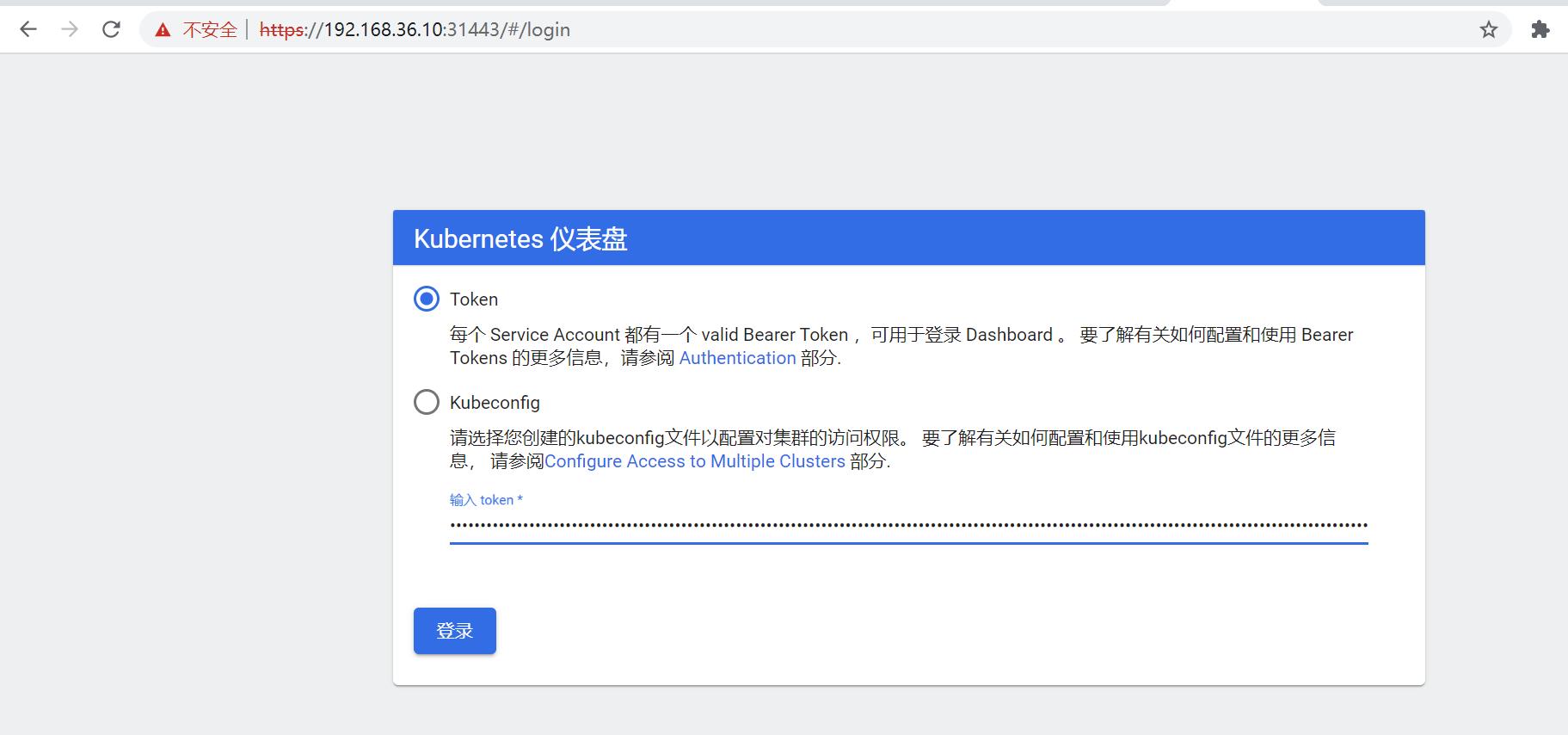
登录成功
Dashboard的使用在此不做过多说明。